PageInsight - A Smarter Way to Read the Web
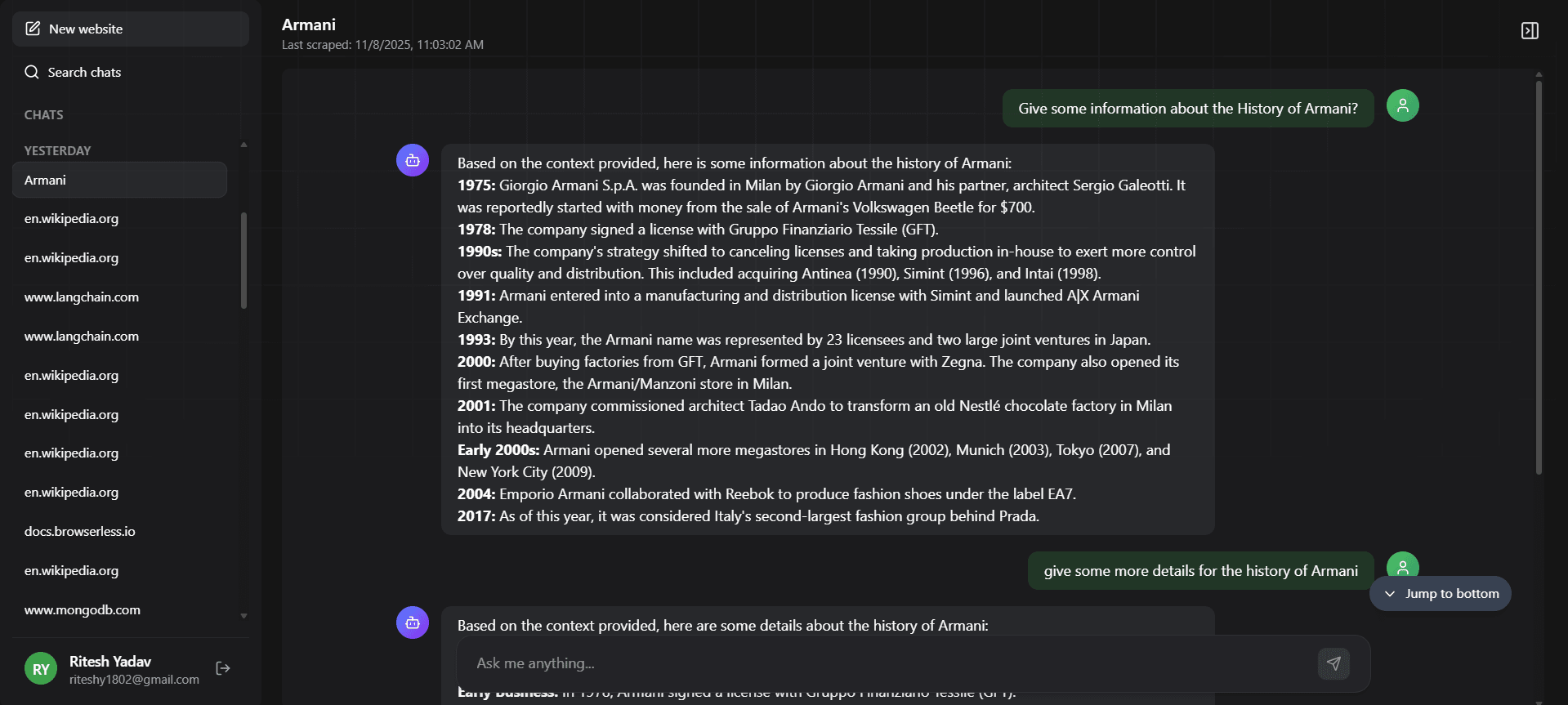
This application uses a Node.js/Express API to handle user requests, which are then passed to a BullMQ (Redis) queue. Separate Background Workers listen to this queue to perform the actual processing. For website ingestion, a worker receives a URL, scrapes its content using a headless browser, breaks the text into "chunks," converts these chunks into vector embeddings (e.g., via Gemini), and stores them in a PostgreSQL database with pgvector. When a user asks a question, a similar RAG (Retrieval-Augmented Generation) process occurs: a worker embeds the question, queries pgvector to find the most relevant text chunks from the source, and then feeds both the question and this retrieved context to an LLM to generate an answer grounded in the original data.
09 Nov 2025
👀 Project details
Full Stack Developer Internship at Second Brain Labs
Internship / Remote / Immediate JoiningStipend: ₹25–40k/month (based on skills)Read the JD here: Job DescriptionExperience: Minimum 1+ years of hands-on development experience📈 Internship will be convertible to full-time (2-3 months based on performance) Assignment OverviewYou’ll build a small...


